

.png)

.png)
Eppo News
Eppo Is Now Part of Datadog!
This acquisition will drive learning velocity for all Eppo customers, equipping them to expand experimentation across their organizations
Learn more


Successful acquisitions are based on what makes sense for customers. For Eppo’s experimentation customers, there was no better fit than the world’s leading observability platform in Datadog, where product development teams already turn to understand the “why” behind application issues.
Since the deal closed, we’ve been building observability-native feature flagging and a next-gen approach to experiment diagnostics and deep-dives. Building these new products has given us a unique opportunity to build upon what we learned at Eppo and make improvements that would be hard to do in the confines of our “v1”. Today, we’re focused on solving what we consider to be the three biggest problems in experimentation.
The first problem is that, for all of the advanced statistics available to speed up testing, most of the time lost when running experiments is due to more mundane issues (i.e. bugs) that require discarding results and re-starting. It’s a pain to realize after a few days of runtime that the experiment is broken on an old version of Internet Explorer, there’s a UX degradation on a specific viewport size, or a key instrumentation event is missing on Android. These stop-starts end up taking as much time as the experiment itself.
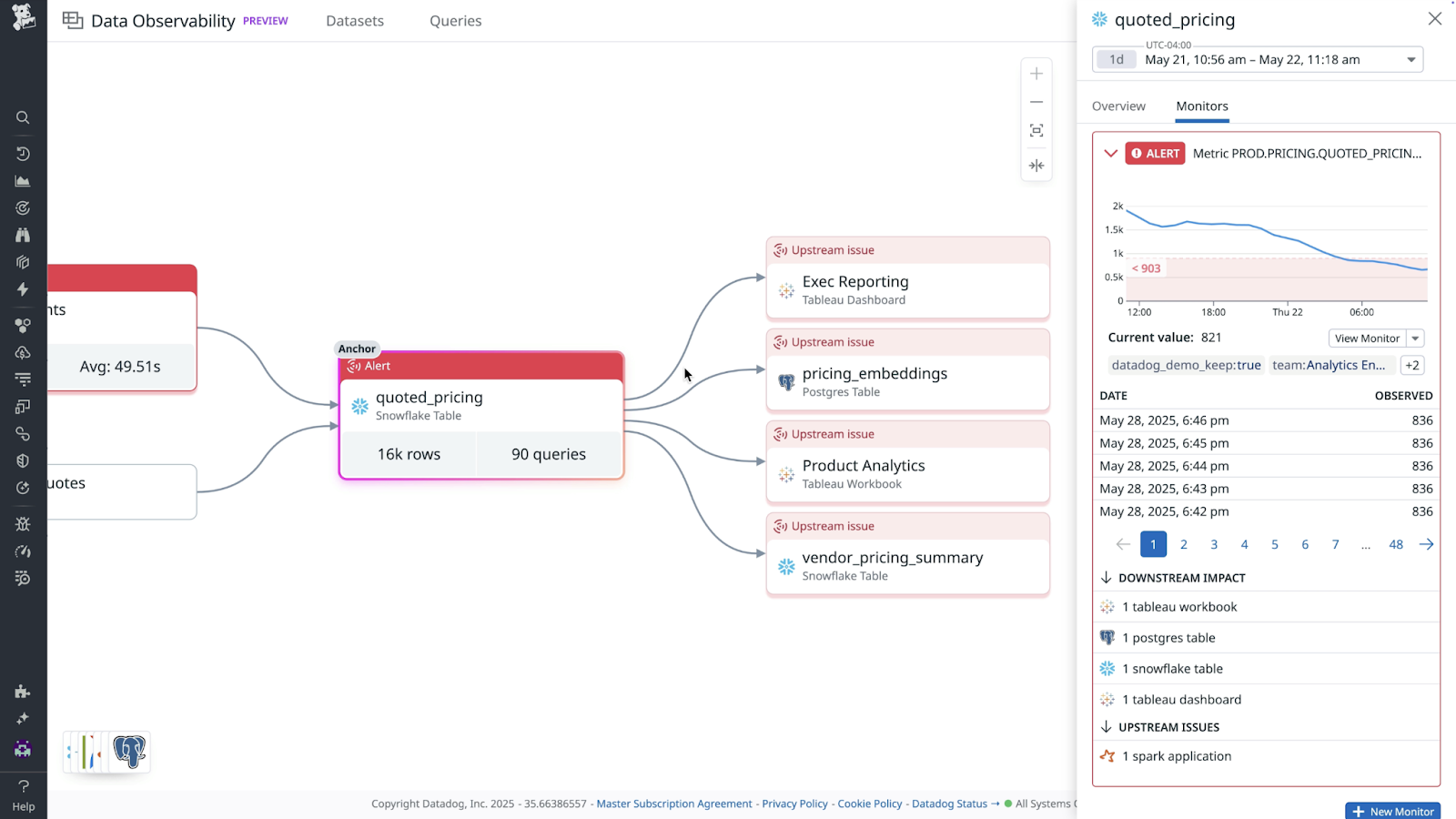
The second problem is that commercial tools lack first class support for canary release testing. Experimentation discourse usually focuses on scientific thinking and finding wins, but the largest experimentation programs in the world like Netflix, Uber, or Microsoft are built on a foundation of comprehensive canary testing. By automatically turning code release workflows into randomized experiments, engineers build experimentation muscles and learn statistical thinking. The problem for most companies is that executing canaries in this way is too manual and requires engineers to babysit every release (often leading them to navigate to Datadog or similar products).

The third problem is that the amount of insight and intelligence generated per experiment is still lower than it could be. The “state of the art” approach to experiment deep-dives often looks like slicing experiment results by every possible segment, looking for a smoking gun explanation of why the experiment isn’t successful. Hopefully, these teams are at least aware that their "multiple testing” is bound to lead to plenty of false positives. But even when teams correctly identify an underperforming segment, they still need to root-cause to the specific issue, whether it be confusing UX, poorly-aligned personalization, or something less apparent like application slowness.
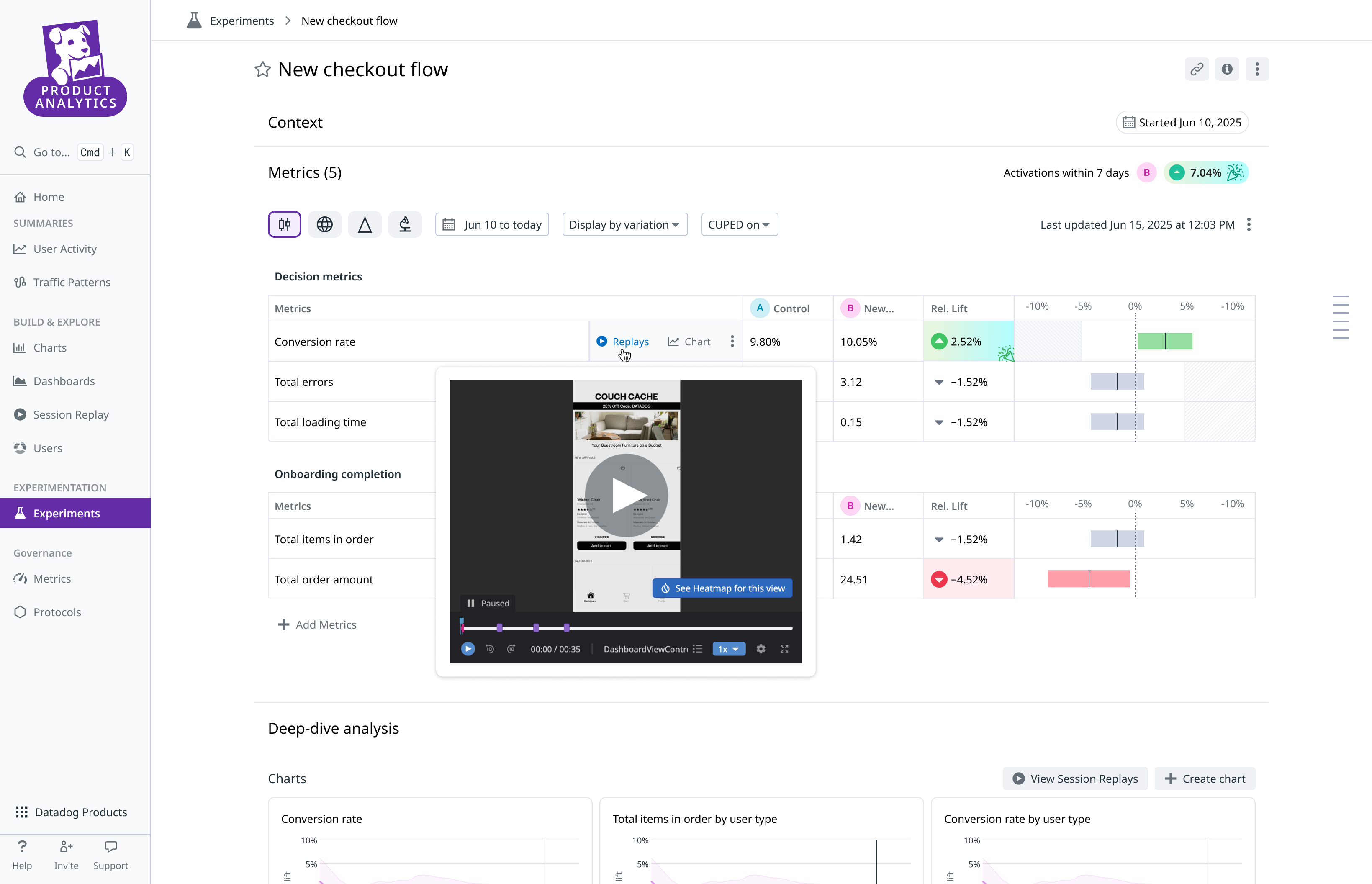
Partnering with Datadog immediately gave us tools for solving each of these top problems in experimentation. Real-time observability metrics helped us leapfrog into an exciting new suite of experiment diagnostics, so engineers can catch product bugs and experiment issues right as they turn on the test. Statistical canary testing can now be automated based on errors, infra metrics, and product telemetry. And stay tuned for a new spin on experiment deep-dives that weaves the universe of data that Eppo and Datadog bring together, including warehouse metrics, behavioral events, and application vitals.
The Eppo team (and me as CEO) are still 100% focused on experimentation, and Datadog brings a wealth of experience of enterprise support. Today, we’re excited to share that interested teams can request access to our new Datadog Feature Flags as part of Datadog’s Product Preview program.
We’ll be sharing a lot more of what we’re building this fall, including in-person at EXL, MIT CODE, and AWS re:invent. More to come soon!
-Che & the Eppo team







